
In recent years, Generative Artificial Intelligence (GenAI) has emerged as a transformative force across industries. Unlike traditional AI systems that analyse data to make predictions, Gen AI models, such as OpenAI's ChatGPT and Meta’s Llama have the capability to create new content including text and images. As businesses and organisations look to harness GenAI to push through efficiencies and find new revenue streams, they must do so within a responsible AI framework. This involves understanding the opportunities these new technologies offer as well as the limitations and risks.
In January 2024 the UK government published the Generative AI Framework for HMG which sets out ten guiding principles for the safe, responsible, and effective use of Gen AI. While these principles are specifically designed with government bodies in mind, they are a good foundation for any organisation looking to implement AI responsibly. In this blog, I outline key factors to consider when developing an evaluation strategy. By adopting a comprehensive evaluation strategy aligned with these ten principles, organisations can harness the full potential of Gen AI, confidently navigate its limitations, and effectively manage associated risks.
Approach to quality assurance
The approach to quality assurance in Gen AI systems centres on evaluation. Unlike traditional testing in software applications, where functionality is validated against fixed criteria, evaluation in Gen AI systems encompasses a broader function, measuring not only the content of the response but also its quality. For example, how coherent and therefore usable an answer is. There are currently three approaches to evaluating text-based Gen AI outputs: human evaluation, traditional machine learning evaluation, and the emerging Large Language Model (LLM) as Judge approach.
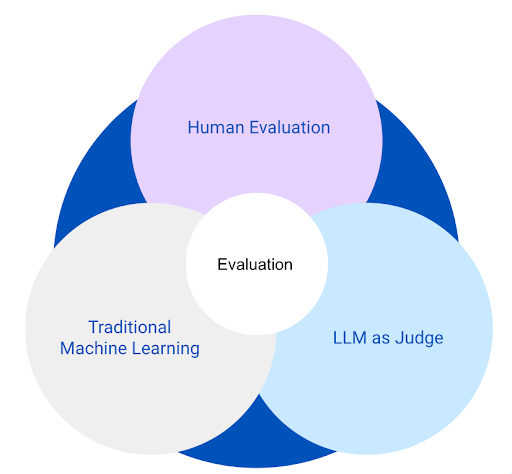
Human evaluations are the starting point and provide both qualitative and quantitative insights, and should continue as part of ongoing monitoring and user feedback. Traditional Machine Learning (ML) and LLM as Judge approaches allow automation and scaling of evaluation. Traditional machine learning measurements, for example, BLEU score, are beneficial when the exact answer is known and generated responses can be compared with this answer. This approach is less suitable when there could be multiple correct responses and in these cases, the LLM as Judge approach can be beneficial. In practice a combination of approaches is likely to provide the best overall evaluation but the degree of implementation of each will be tailored to meet the specific use case.
LLM as Judge
The concept of LLM as Judge is relatively new in the GenAI field. This is an AI assisted method that involves using an LLM to assess the output of another LLM. The LLM as Judge scores the outputs across a range of metrics to quantify performance. This approach has been shown to outperform traditional machine learning measurements for outputs of GenAI, as LLM scores more closely align with human judgements. Additionally, this approach can be relatively fast to implement. Some metrics require a reference dataset that is crafted by subject matter experts and includes real world questions and ‘gold standard’ answers. System responses can be compared with the reference answers and an LLM can be instructed to rate a response against this ‘gold standard’. Importantly this golden dataset should be constantly updated.
An example of a metric requiring reference data is Azure AI’s SimilarityEvaluator. This metric requires a question and expected answer referred to as the ground truth. It uses the LLM to measure the similarity of the generated response to the ground truth.
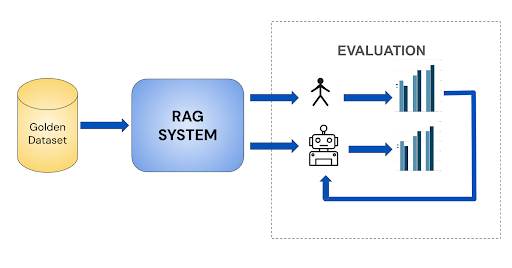
When using automated evaluations they must be validated to ensure they accurately reflect the performance of the AI system and align with human assessments. Feedback loops (Figure 2) from human assessments play a crucial role in refining automated evaluation. As systems evolve it will be necessary to iterate on the evaluation criteria so a cycle of validation and iteration should be embraced by organisations.
Selecting LLM models and metrics
When using the LLM as Judge approach, selecting the appropriate models and metrics are key decisions to ensuring effective evaluation. Different LLMs can vary in accuracy, scalability, and cost, and each factor plays a role in determining which model best suits a specific use case. Examples of models include GPT-3.5, GPT-4o or Llama3. The model selection will also influence how custom evaluations are crafted. For example, GPT-3.5 typically requires a few-shot approach when engineering evaluation prompts; whereas this is less critical with GPT-4o. Data privacy is also a critical consideration when selecting an LLM as a judge. If private data is being evaluated, it is essential to ensure that the chosen model does not use outputs for training or fine-tuning models. Models like Azure OpenAI offer such safeguards, but it may still be necessary to opt out of specific services.
When selecting the appropriate range of metrics to measure, this must be tailored to meet specific business requirements. In a tool which is public facing there may be more of a focus on safety metrics than, for example, an internal tool used by trained professionals. As part of determining key metrics it is also important to consider the best scoring system to implement. This may involve thinking about the balance between granularity and explainability. For example, a 5 point scoring system while less granular than a 10 point system, may be easier for users to understand and apply, resulting in more consistent judgements. This is important when assessing the alignment of LLM scores with human scores.
The table below shows an example scoring system for a similarity metric.
|
Score |
Score Description |
|
1 |
Generated response is not at all similar to expected response |
|
2 |
Generated response is mostly not similar to expected response |
|
3 |
Generated response is somewhat similar to expected response |
|
4 |
Generated response is mostly similar to expected response |
|
5 |
Generated response is completely similar to expected response |
Evaluation-driven development
Evaluation-Driven Development (EDD) is similar to Test-Driven Development (TDD), in that it uses continuous evaluation to guide refinement and enhancement in Gen AI systems. Just as TDD relies on iterative testing to ensure code quality, evaluation-driven development uses evaluation feedback to inform ongoing adjustments. This iterative cycle of evaluation, feedback, and adjustment enhances quality ensuring that outputs align with both practical demands and user expectations and can highlight any potential risks. The chosen metrics must offer actionable insights meaning they must point to a course of action. By embedding evaluation throughout development, organisations can ensure that AI systems are consistently optimised for real-world applications.
Frameworks for evaluation
Tools, such as the Azure AI Evaluation SDK, and open source frameworks, such as RAGAS and DeepEval, enable streamlining the implementation of evaluation through data orchestration, and many come with built-in metrics for assessing aspects, such as quality and safety. The RAGAS framework is particularly beneficial in evaluation of Retrieval Augmented Generation (RAG) systems. These systems are commonly used with Gen AI to optimise outputs by integrating data retrieval processes. This allows the incorporation of up-to-date and context-specific information in the responses generated by LLMs. RAGAS enables component-level evaluation by providing metrics to assess both the retrieval and generation parts. In many use cases, it will be necessary to develop custom evaluators to address unique business requirements. By leveraging both out-of-the-box and custom evaluations, organisations can build a robust set of evaluation metrics.
Evaluation is vital for effective quality assurance and the responsible development and operation of applications and systems using Gen AI and RAG. In this blog I have discussed an approach to evaluation, as well as highlighting some open source frameworks and tools that can assist in its implementation. By implementing a robust evaluation strategy, organisations can ensure that their Gen AI deployments are safe, responsible, and effective, and thereby leading to greater confidence in harnessing these new technologies.

Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-

-

Reimagining case management across secure government
Read blog post -
