
Having lived and breathed Microsoft for over 20 years, it is important to sometimes stop and think about all the changes over those years and all the growth and learning gained from each change to the analytics space.
When I first started working with Microsoft Products, everything was On Premise. We had a large room full of Microsoft 2000 servers and a long journey to finally upgrade to 2008 R2. Integration Services was the orchestration tool of choice and Reporting Services (SSRS) was the server based reporting tool.
We were starting to move from basic management reporting into business intelligence, especially with the introduction of SQL Server Analysis Services that became part of the environment when we finally pushed to 2008 R2.
We have come a long way since those days…
On Premises Analytics
One of the biggest issues with On Premise was upgrading to new servers. This was never easy and sometimes couldn’t be done because of the systems it supported, this led to a real disparity of servers. Some stayed at 2000, some moved to 2008 R2, and a few lucky ones were upgraded to later versions.
Another big issue, especially for the analytics team, was using the servers. Spinning up a new database required a lot of work to make sure that whatever was needed wouldn’t run out of space or memory. There was only a certain amount of these resources for all services, leading to some projects simply not being able to go ahead.
There’s nothing more frustrating as a developer than knowing there are later releases out there but you are stuck on an old version. Or knowing that you could do so much more with a bit more compute power and space allocation. There was no room to grow. You had to understand your full limits and work from there.
Reporting Services (SSRS)
It's interesting to look back on SSRS, Microsoft’s Paginated reporting original solution after using Power BI for so long now. Yes, it delivered fairly basic paginated reporting,but it didn’t quite deliver the experience we really wanted for our new Business Intelligence vision.
On Premises to Azure
A career move presented me with the opportunity to start using Azure and Power BI. Finally, the floodgates seemed to open and new possibilities appeared endless. Here are just a few examples of the changes happening at this point:
-
Azure allowed us to always be on the latest version. No more wishing that I could use SQL Server 2014 whilst stuck on 2008 R2.
-
Power BI, interactive data visualisation was a complete game changer (We will look at this more later).
-
Azure SQL Databases meant we could spin up small, cheaper solutions for development work, scaling up as we go. We never needed to pay for more than we used. We even had the advantage of upping compute during peak loading times while always being on the latest version and so many possibilities of choice.
-
We can still work with our SQL skills building stored procedures to transform data.
-
Azure Data Lake: secure cloud storage for structured and unstructured data. A landing area for our data that also creates opportunities for our Data Science experts.
-
Azure Data Warehouse (Which upgraded to Synapse in 2019) was the offering that allows for MPP - Massively parallel processing for big scale data. Along with the serverless SQL Pools (Synapse) to finally give us the chance to do analysis and transformations on the data pre the SQL Database load.
-
Data Factory: the Azure data orchestration tool. Another big gamechanger, offering so much more flexibility than Integration Services. Having a solution that can access cloud resources and on premises resources. So much connectivity.
Power BI
Power BI is Microsoft’s modern analytics platform that allows users to shape their own data experience, including:
-
drilling through to new details.
-
drilling down into hierarchies.
-
filtering data.
-
using AI visuals to gain more insight.
-
better visuals
At the heart of everything was the Power BI Tabular storage model. The Vertipaq engine meant we could create reports that span over multiple users who could all interact with them while sending queries to the engine at speed.
I have worked with Analysis Services in the past, along with SSRS. Creating Star Schemas sitting in columnar storage without needing to set up Analysis Services was a huge win for me as it was a much easier process.
Of course, you can’t talk about Power BI without understanding how each licence experience is. From the Power BI Pro Self Service environment, through to Power BI Premium Enterprise Level License. There have been a lot of changes and Premium continues to create fantastic additional functionality. Premium sits on top of the Gen 2 Capacity offering larger model sizes, more compute. Etc.
As a takeaway when using Pro, you should always work with additional Azure resources(like Azure SQL DB, Integration Services etc.) to get the best end product.
With Azure and Power BI we have worked with the recommended architectures and produced quality analytics services time and time again. But, there were still some issues and pain points along the way, and this is where Fabric comes in…
Fabric
Fabric is the Software as a Service (SaaS) solution, pulling together all the resources needed for analytics, data science and real time reporting. Fabric concentrates on these key areas to provide an all in one solution.
For an analytics project and working with customers, our (basic) architecture for analytics projects was as follows:
-
extract data into a Data Lake using Integration Services on a schedule
-
load the data into SQL Server Database
-
transform the data into STAR schema (Facts and Dimensions) for Power BI analytics
-
load the data into Power BI (Import mode wherever possible but there are opportunities for Direct Query, and Composite modelling for larger data sets)
We can see here that the data is held in multiple areas:
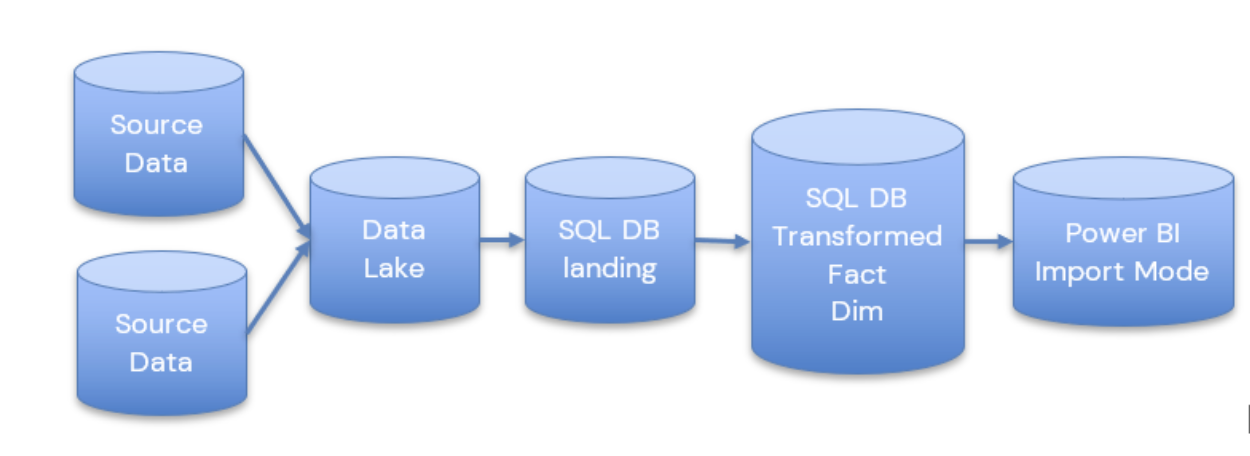
Synapse starts to address this with the Serverless SQL Pools. We can now create Notebooks of code to transform our data on the file itself, rather than in the SQL Database on the fully structured data.
Fabric has completely changed the game. Let's look into how in a little more detail.
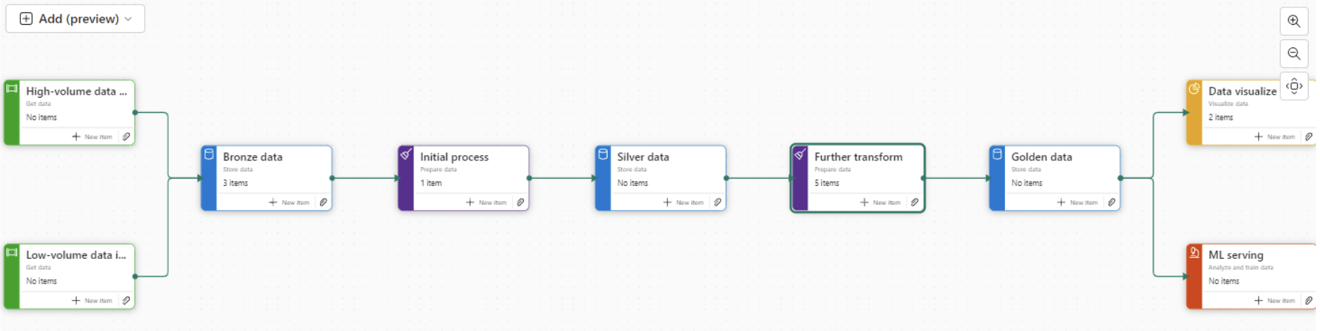
Medallion architecture
First of all, we need to understand the architectures we are working with. The medallion architecture gives us specific layers
-
Gold - our landing area. The data is added to the lake. As is. No Processing
-
Silver – the data is transformed and processed
-
Gold – the data is structured in a way that can be used for Analytics. The star schema for Power BI.
Fabric allows us to work with the medallion architecture seamlessly, and as announced at Microsoft build in May 2024, we now have Task Flows to organise and relate resources. The Medallion architecture is one of the Flows that you can immediately spin up to use.
Delta Lake
The Delta Lake enhances Data Lake performance by providing ACID transactional processes.
A – Atomicity, transactions either succeed or fail completely.
C – Consistency, ensuring that data remains valid during reads and writes
I – Isolation, running transactions don’t interfere with each other
D – Durability, committed changes are permanent. Uses cloud storage for files and transaction logs
Delta Lake is the perfect storage for our Parquet files.
Notebooks
Used to develop Apache Spark jobs so we can now utilise code such as Pyspark and transform the data before adding into a new file ready to load.
Delta Parquet
Here is where it gets really interesting. In the past, our data has been held as CSV’s, txt etc. Now we can add Parquet, an open source, columnar storage file format, into our architecture.
The Power BI data model is also a columnar data store. This creates really exciting opportunities to work with larger models and have the full suite of Power BI DAX and functionality available to us.
But Fabric also allows us to create our Parquet Files as Delta Parquet, adhering to the ACID guarantees. The Delta is an additional layer over Parquet which means we can do such things as time travel with the transaction log. We can hold versions of the data and run VACUUM to remove old historical files not required anymore.
Direct Lake Mode
Along with Parquet, we get a new Power BI Import mode to work with. Direct Lake allows us to connect directly to Delta Parquet Files and use this columnar data store instead of the Power BI Import mode columnar model.
This gives us a few advantages:
-
it removes an extra layer of data
-
our data can be partitioned into multiple files and Power BI can use certain partitions, meaning we can have a much bigger model.
-
We have Direct Query, running on top of a SQL DB is only as quick as the SQL DB In this mode you can’t use some of the best Power BI Capabilities like DAX Time Intelligence. With Direct Lake you get all the functionality of an Import model.
SQL Analytics Endpoints
If you are a SQL obsessive, like myself you can analyse the data using the SQL analytics endpoint within a file. No need to process into a structured SQL Database
Data Warehouse
Another one for SQL obsessives and for Big Data reporting needs. There will be times when you still want to serve via a structured Data Warehouse.
Conclusion
Obviously, this is just a very brief introduction to Fabric and there is so much more to understand and work with. However, using the Medallion architecture we can see a really substantial change in the amount of data layers we have to work with.
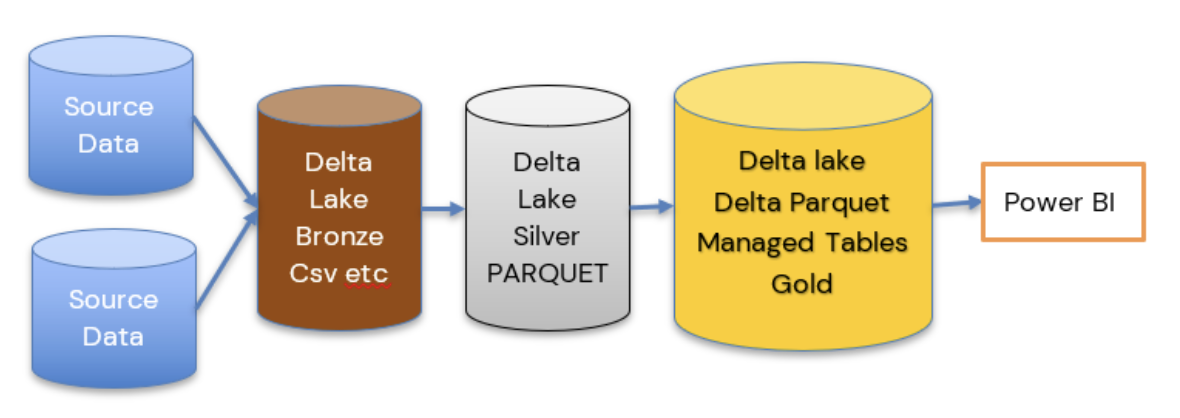
And the less we have of data copies, the better our architecture will be. There are still a lot of uses for the Data Warehouse but for many smaller projects, this offers us so much more.
It's been a long journey and knowing Microsoft, there will be plenty more fantastic new updates coming. Along the way, I would say that these three ‘jumps’ were the biggest game changes for me, and I can’t wait to see what Fabric can offer.
And remember, always use a STAR schema.

Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-

Reimagining case management across secure government
Read blog post -

-
