A Linked Data approach
Bringing data together from multiple sources enables greater insights but is often challenging since the data has not been created to be interoperable. Often data is created using only locally meaningful identifiers and structure, which means work needs to be done to connect them in order to make use of them together. Linked Data, however, uses global identifiers to identify the same concept in different data sources and connect from one source of data to another.
Linked Data is an approach to publishing data so it becomes a machine processable web of data which you can access on the internet. Much like standard web pages are a web of documents connected by hyperlinks; Linked Data lets us create a world wide web of data where data items are connected with hyperlinks. Data explorers can access data, interpret it, and follow links to more data. It is an approach to make your data FAIR (Findable, Accessible, Interoperable and Reusable).
Linked Data Principles
The Linked Data Principles were published by Tim Berners-Lee, the inventor of the Web, in 2006 and state that:
- Things within your data should be identified by Uniform Resource Identifiers (URIs);
- URIs should be resolvable on the Web by using HTTP identifiers;
- Useful information should be returned when an URI is resolved;
- Link to other things by reusing their URIs.
By publishing data following these principles, data is retrievable over the web and interlinked with other data, i.e. forming a web of data.
Dark side of the moon
We'll now discuss each of these principles and illustrate their use with an example containing data about Pink Floyd’s album “Dark Side of the Moon”.

The first principle ensures that things described within the data are given globally unique identifiers. This relies on data publishers only using URIs within the range of URIs that they own, i.e. within their own Internet domain. For our example, one identifier that exists for the Dark Side of the Moon album is this URI:
http://musicbrainz.org/release-group/f5093c06-23e3-404f-aeaa-40f72885ee3a
This is an identifier from the MusicBrainz service which they have created for the purpose of providing information about the album.
The second principle ensures that data is retrievable using standard web protocols. HTTP is a well established mechanism for retrieving content on the web, and is what you used to retrieve this web page. It is also widely used in REST APIs. Using the Pink Floyd example, if we visit our URI in a browser, e.g. by clicking the link above, then we see that we get a web page back.
The third principle covers what is returned to a user when dereferencing a URI. The user should be able to request the content in the format that they require, which is possible through content negotiation. For humans using a web browser, this will result in the HTML representation being retrieved which can be displayed in the browser as a web page. However, machines can use this mechanism to retrieve a data representation format such as RDF that will allow them to reuse the data directly in other applications. For our Dark Side of the Moon example, we can use a cURL command to retrieve a JSON-LD representation of contents of the page.
curl -L -H 'Accept: application/ld+json' http://musicbrainz.org/release-group/f5093c06-23e3-404f-aeaa-40f72885ee3aThe -L parameter states that when dereferencing the page, redirects to new locations should be followed. This is needed since for security purposes, the resource is retrieved from the HTTP with TLS encryption location. With the -H parameter we state that we want the JSON-LD representation returned. The Image below shows some of the JSON-LD content retrieved in April 2023.
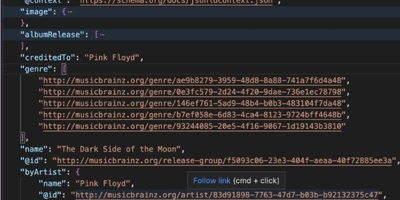
The final principle ensures that data is connected to relevant related data, i.e. it is linked to form a web. Data explorers can 'follow their nose' to retrieve more data by following these links, much as humans follow links to retrieve web pages on related topics. In the example content above, there are links to other pages within MusicBrainz site, e.g. to the page about Pink Floyd identified with the URI
http://musicbrainz.org/artist/83d91898-7763-47d7-b03b-b92132375c47.The sameAs links also include items on external sites such as
"http://www.musik-sammler.de/album/20278",
"http://www.wikidata.org/entity/Q150901", "https://rateyourmusic.com/release/album/pink_floyd/the_dark_side_of_the_moon/",
"https://www.allmusic.com/album/mw0000191308",
"https://www.discogs.com/master/10362",
"https://www.offiziellecharts.de/album-details-6346"This allows the user to find more information about the album from a variety of sources.
Note that the Linked Data principles do not require data to be openly published. The principles can be applied within an organisation's Intranet to provide an internal web of data, or even a web of data that links internal and external data. Intranets already contain links to both internal and external documents. The same principles apply here but for data.
5 Star Data
Closely related to the Linked Data Principles is the notion of 5 Star Data which provides a set of guidelines for publishing data in an open and linked manner.
The five stars of open data publishing are:
⭐ Publish your data with an open license (e.g. a PDF or an image);
⭐⭐ Publish your data in a machine-readable structured format (e.g. a spreadsheet);
⭐⭐⭐ Publish your data in a non-proprietary format (e.g. CSV file);
⭐⭐⭐⭐ Identify the things in your data so that people can point at specific items;
⭐⭐⭐⭐⭐ Include links in your data to other people’s data.
The first star ensures that data consumers understand the conditions in which they can reuse the data. Licenses can be applied to data in any format, including those embedded within PDF documents. For a detailed discussion on data licenses, see The Turing Way – Data Licenses.
The second star ensures that the openly published data can be more easily reused since it is published in a machine readable format. However, the third star takes this one step further by ensuring that consumers are not required to have specific proprietary software to reuse the data.
The fourth and fifth stars focus on linking the data with other sources. The fourth is about identifying things so that others can link to them, while the fifth is about providing links from your data to other people’s data. RDF provides a natural mechanism for satisfying the fourth and fifth star but they can also be realised in other formats, e.g. the links provided in JSON:API.
As a minimum standard for Open Data publishing, data providers should aim for ⭐⭐⭐ (three stars). At this level, the data is available with a clearly defined license in a widely reusable format, so users don't need certain software to access it. However, the consumer will be required to spend more time with the data to fully understand the modelling and representation within the data. Much of the data in the UK open data portal is ⭐⭐⭐ (three stars) open data as it is published under the Open Government License in either CSV or XML formats. To further increase how useful, and usable, this data is, and to make it more FAIR, it should be published as ⭐⭐⭐⭐⭐(five star data). This is Linked Open Data, such as the data published by the Office for National Statistics (ONS) in their Integrated Data Portal or the Statistics Scotland Data Portal from the Scottish Government.
Linked Open Data
By following the Linked Data Principles and conforming to the 5 Star Data Guidelines, datasets are deemed to be published as Linked Open Data. The image below shows the Linked Open Data Cloud which captures some of the datasets that have been published in this way. Notable datasets within this collection are DBPedia, GeoNames, and Wikidata, which have acted as central hubs through which other data is linked. Below is the November 2022 Linked Open Data Cloud from https://lod-cloud.net/ which contains 1,255 datasets classified into 9 domains.


Our recent tech blog posts
Transformation is for everyone. We love sharing our thoughts, approaches, learning and research all gained from the work we do.
-

-

Reimagining case management across secure government
Read blog post -

-
